The BibGlimpse
package comes with an automated setup script. A standard
installation under Linux is hence achieved
in four steps:
| wget http://bioinf.boku.ac.at/bibglimpse/bibglimpse.tar.gz; |
| tar -xzf bibglimpse.tar.gz; |
| cd bibglimpse; |
| emacs BibGlimpse.SETUP; |
| ./BibGlimpse.SETUP; |
Upon successful installation, you can then access BibGlimpse from your web browser:
http://localhost:4080/cgi-bin/BibGlimpse/wrrepos.cgi?ID=1
Detailed informations about requirements
before installation, the steps performed by the BibGlimpse.SETUP script, as well as how to configure BibGlimpse to work with an existing
Apache server are documented below.
BibGlimpse builds on the established Webglimpse search software, which in turn relies on the glimpse search engine. While glimpse is coded in C, BibGlimpse and Webglimpse are mainly written in Perl with some additional BASH scripts to interface with the glimpse executables and the pdftotext converter, that transforms PDF files into plain text. Web access to BibGlimpse and Webglimpse is provided by an Apache server supporting CGI. Your system therefore needs to meet the following requirements, in order to run BibGlimpse:
In case you do not have an Apache server installed, the BibGlimpse package provides the option to automatically compile Apache 2.2.9 in a non-privileged, local path according to the Apache Installation documentation To do that manually, rather than from BibGlimpse.SETUP, just run
| tar -xzf bibglimpse.tar.gz; |
| cd bibglimpse/apache; |
| tar -xzf httpd-2.2.9.tar.gz; |
| cd httpd-2.2.9.tar.gz; |
| ./configure --prefix=/some/local/path; |
| make; |
| make install; |
| cd /some/local/path; |
and start the server on a non-standard port, e.g., on port 4080:
| mv conf/httpd.conf conf/httpd.conf.old |
| sed -e "s^Listen 80^Listen 4080^" < conf/httpd.conf.old > conf.httpd.conf; |
| ./bin/apachectl -k start; |
There are actually only two things that one needs to specify for running the BibGlimpse.SETUP:
Both are defined by editing the corresponding variables in BibGlimpse.SETUP directly:
| # Define BibGlimpse installation path |
| WG2PRE="/some/local/path/BibGlimpse"; |
| # Install Apache locally ... |
| LOCAPA='Y'; # [Y/N] |
| # ... OR use an existing Apache |
| APSERVERURL="your.server.cc"; |
| APSERVERPORT="4080"; |
| APHOME="/usr/lib/apache"; |
| APHTTPDCONF="$APHOME/conf/httpd.conf"; |
| APHTDOCSLOC="$APHOME/htdocs"; |
| APCGILOC="$APHOME/cgi-bin"; |
| APCGIWEB="cgi-bin"; |
| APWEBUSER="nobody"; |
Required Apache information includes the server name and port, paths
to the httpd.conf file, the htdocs/ and the
cgi-bin/ directory plus the equivalent URL on the server, as
well as the name of the web user running the Apache. Moreover, you
need to have permission to write into Apache's htdocs/ and
cgi-bin/ directories, both as yourself and as the web user
running the server. To this end, you might want to consult the
sysadmin in charge of the Apache. Note that all the Apache settings
become irrelevant, when a local installation is performed
(LOCAPA='Y').
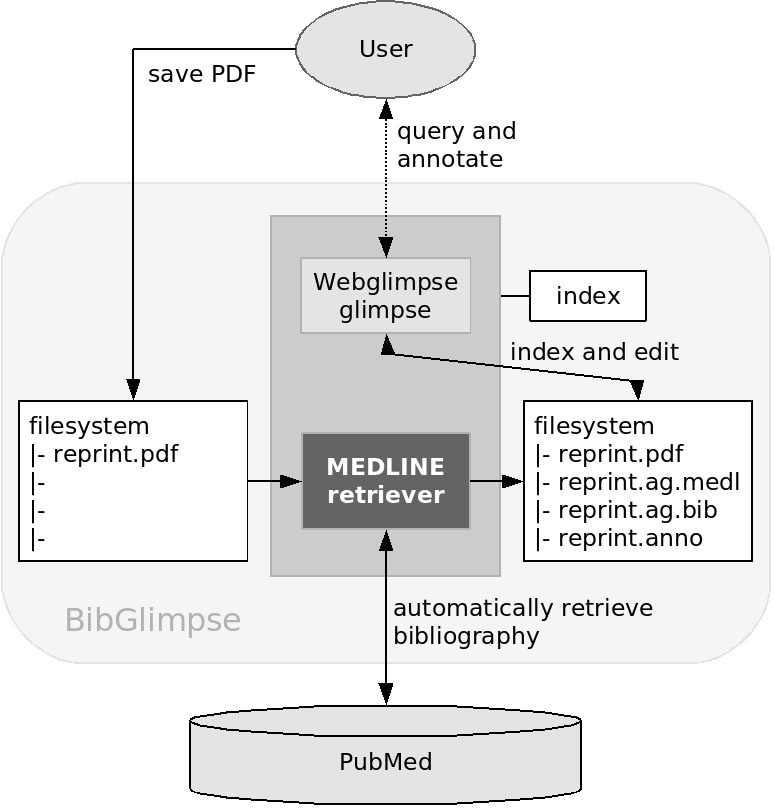
BibGlimpse extends Webglimpse's PDF indexing feature with automated bibliography retrieval from PubMed and by supporting user annotations.
Technically, BibGlimpse consists of three parts:
Glimpse provides the powerful file indexing and query engine to make large collections of texts full-text searchable. It is a command line tool and was first developed by Udi Manber, Burra Gopal and Sun Wu at the University of Arizona in the early 90's.
Webglimpse is a web interface to search and manage archives indexed with glimpse. It has been widely used for over 10 years now and is maintained by Golda Velez.
BibGlimpse adopts Webglimpse's capability to index PDF files to enable its usage as a scientific reprint management tool. It adds automated bibliography retrieval from PubMed (implemented as a MEDLINE retriever Perl script) and supports user annotations.
Setting up BibGlimpse therefore comprises subsequent installation of glimpse and Webglimpse. With BibGlimpse code being woven into the Webglimpse package, some final modifications are then sufficient to enable the BibGlimpse features. Despite all these steps,
being automated in the BibGlimpse.SETUP
script, we will nevertheless give a detailed description for each
of them below. In addition there is also extensive documentation
available from the Webglimpse
installation site.
The glimpse source code is included in the BibGlimpse package. It is unpacked and compiled according to:
| wget http://bioinf.boku.ac.at/bibglimpse/bibglimpse.tar.gz; |
| tar -xzf bibglimpse.tar.gz; |
| cd bibglimpse/glimpse; |
| tar -xzf glimpse-latest.tar.gz; |
| cd glimpse-4.18.5; |
| ./configure --with-file-end-mark='\t' --enable-structured-queries; |
| make; |
| make install; |
This will try to install glimpse in /usr/local/bin. If you do not have root rights, or if you want to install into another path, you will want to change this using configure with the --prefix flag or according to the Configure and Install glimpse section of Webglimpse. Either way, you need to remember where you installed the glimpse binaries to.
As a short sanity check of your glimpse installation, build and search a structured index for two files including blanks in the filenames with:
| mkdir files; |
| echo -e "@FILE{ test\nfieldA{7}:\tbla bla\nfieldB{3}:\tfoo\n}" > files/test\ 1.txt; |
| echo -e "@FILE{ test\nfieldA{7}:\tfoo bla\nfieldB{3}:\tbla\n}" > files/test\ 2.txt; |
| glimpseindex -s -H . files/*; |
| glimpse -y -H . fieldA=foo; |
If glimpse is installed properly, this will find exactly one hit for
fieldA containing foo in files/test 2.txt.
Webglimpse has its own installation script. Interactively, it determines the web server configuration, compiles two short programs and creates the Webglimpse CGI scripts in the appropriate web server paths. A detailed description of all the information prompted is given on the Webglimpse Installation site. Starting from the BibGlimpse package this script can be called with
| tar -xzf bibglimpse.tar.gz; |
| cd bibglimpse; |
| ./wginstall; |
Note that the BibGlimpse.SETUP executes wginstall with,
| cat wgInput.txt | perl wginstall | tee wgInput.log; |
such that all handled parameters can be found in wgInput.txt
and the corresponding output is entirely logged in
wgInput.log. If you happen to encounter a problem installing
Webglimpse, these files might thus contain helpful information. Note
that these files also define the Webglimpse administrative login and
password with the default admin and admin.
To enable the BibGlimpse features, the standard Webglimpse distribution needs to be adapted appropriately (exchanging some files, setting some flags and paths).
The main purpose of these modifications is to make Webglimpse index PDFs with xpdf's pdftotext command. The 'Indexing PDF documents with xpdf' page describes the procedure to enable this Webglimpse feature in detail. For BibGlimpse, however, the relevant shell script usexpdf.sh was further extended, such that it does not only convert a PDF to text, but that it also calls the BibGlimpse script wrMedline.pl to retrieve the corresponding MEDLINE entry for the PDF in question.
To search PDFs and bibliography via Webglimpse's webinterface webglimpse.cgi, the above modifications would be sufficient. For appropriate display of bibliography and online editing of annotations, however, BibGlimpse provides its own interfaces wrsearch.cgi and wrrepos.cgi. The last modifications, hence, enable the usage of these two CGI scripts. Comments and explanations how the BibGlimpse.SETUP makes all these modifications are available in the script itself.
Besides looking at the output from running BibGlimpse.SETUP, you can also manually check if all adaptions have been made properly. In order to do so, search for the following patterns and files in the installations paths $WG2PRE and $APCGILOC, that you previously specified (If you have chosen the local Apache installation with LOCAPA='Y', set $APCGILOC=$WG2PRE/BibGlimpse/apache/cgi-bin for the commands below). Lines marked '#' show the expected output:
| grep -rl 'Bioinformatics' $WG2PRE/BibGlimpse/wg2/lib/usexpdf.sh; |
| # $WG2PRE/BibGlimpse/wg2/lib/usexpdf.sh |
| grep -r 'pdf' $WG2PRE/BibGlimpse/wg2/templates/.glimpse_filters; |
| # *.pdf |WGHOME|/lib/usexpdf.sh |
| # *.PDF |WGHOME|/lib/usexpdf.sh |
| grep -r 'pdf*' $WG2PRE/BibGlimpse/wg2/dist/wgfilter-index; |
| # Allow \.pdf$ |
| grep -rl '|INDEXDIR| -s -z' $WG2PRE/BibGlimpse/wg2/templates/; |
| # $WG2PRE/BibGlimpse/wg2/templates/wgreindex |
| grep -rl 'FILE_END_MARK = \"\\t\"' $WG2PRE/BibGlimpse/wg2/lib/; |
| # $WG2PRE/BibGlimpse/wg2/lib/wgHeader.pm |
| grep -rl 'WRREPOS = 1' $WG2PRE/BibGlimpse/wg2/lib/; |
| # $WG2PRE/BibGlimpse/wg2/lib/wgHeader.pm |
| grep -r 'my $WEBGLIMPSE_LIB=*' $APCGILOC/BibGlimpse/*; |
| # $APCGILOC/BibGlimpse/wrrepos.cgi: my $WEBGLIMPSE_LIB='$WG2PRE/BibGlimpse/wg2/lib' |
| # $APCGILOC/BibGlimpse/wrsearch.cgi: my $WEBGLIMPSE_LIB='$WG2PRE/BibGlimpse/wg2/lib' |
Before archives can be configured, the web server port needs to be defined in Webglimpse's wgsites.conf file. BibGlimpse.SETUP uses the sed command to edit this file. To check if the port is correctly set to the $APSERVERPORT you specified (or to 4080 if you chose the local Apache installation with LOCAPA='Y'), have a look at this settings file:
| less $WG2PRE/BibGlimpse/wg2/archives/wgsites.conf; |
If server settings are fine, archives can then be configured via the Webglimpse webadmin interface, or via the corresponding command line tool wgcmd (cf. Webglimpse's 'Configuring an Archive' documents). Like for the Webglimpse installation script, you can call this tool manually with
| $WG2PRE/BibGlimpse/wg2/wgcmd; |
The BibGlimpse.SETUP runs this tool by piping it a file with the required parameters, from the directory you unpacked the BibGlimpse package to:
| cat wgcmdInput.txt | perl "$WG2PRE/BibGlimpse/wg2/wgcmd" | tee wgcmdInput.log; |
So like for the Webglimpse installation, the handled settings as well as the received output are logged in wgcmdInput.txt and wgcmdInput.log.
Note that the BibGlimpse.SETUP creates two identical archives to enable indexing in background. To this end, BibGlimpse.SETUP moreover replaces the standard wgreindex script with one like below:
| #!/bin/sh |
| rm -f /tmp/.wg*; |
| WG2ARC1="$WG2PRE/BibGlimpse/wg2/archives/1"; |
| WG2ARC2="$WG2PRE/BibGlimpse/wg2/archives/2"; |
| "$WG2ARC1"/wrwgreindex \$1 "$WG2ARC2"; |
Before indexing, it is necessary to make the the archives directory accessible for the web user. If you have chosen the local Apache installation (LOCAPA='Y'), this is already done, since the user running the BibGlimpse.SETUP is identical with the user running the Apache. If you have installed to an existing Apache, this will most likely not be the case, so the BibGlimpse.SETUP will tell you to change the ownership of the archives directory to the web user:
| chown -R $APWEBUSER $WG2PRE/BibGlimpse/wg2/archives; |
| chmod -R u+w $WG2PRE/BibGlimpse/wg2/archives; |
Note that the chown command requires root rights, so you will probably have to consult the sysadmin managing your Apache server. Alternatively, if you can login as the web user, you can also do a work around the chown, with something like
| cd $WG2PRE/BibGlimpse/wg2; |
| mv archives/ archives.org; |
| sudo -u $APWEBUSER cp -rp archives.org/ archives; |
| sudo -u $APWEBUSER chmod -R u+w archives/; |
Either way, the final step of the BibGlimpse.SETUP is to start indexing. Again, since the archives must be accessible via the web interface, it is important to perform this step as the web user. For the local Apache installation (LOCAPA='Y'), this is simply achieved by
| cd $WG2PRE/BibGlimpse/wg2/archives/1; |
| ./wgreindex; |
whereas users who installed to an existing Apache will have to run
| cd $WG2PRE/BibGlimpse/wg2/archives/1; |
| sudo -u $APWEBUSER ./wgreindex; |
By that time, you should have created a file structure like in the example installation.
$WG2PRE/BibGlimpse/prints is the indexed reprints directory, containing PDFs (by default two sample PDFs come with the package) as well as the automatically retrieved MEDLINE and BibTeX entries:
| ls $WG2PRE/BibGlimpse/prints; |
| # 15601819.ag.bib |
| # 15601819.ag.medl |
| # 15601819.pdf |
| # v27p1517.ag.medl |
| # v27p1517.ag.bib |
| # v27p1517.pdf |
According to your Apache settings, the BibGlimpse search mask will be accessible via:
http://$APSERVERURL:$APSERVERPORT/$APCGIWEB/$WG2NAM/wrsearch.cgi?ID=1
By default reindexing is triggered upon uploading new files via the web interface, or upon modifying an annotation there. A manual cleaning of the index and reindexing can be triggered by calling:
| rm $WG2PRE/BibGlimpse/wg2/archives/1/.cache/*.abra; |
| $WG2PRE/BibGlimpse/wg2/archives/1/wgreindex; |
To periodically reindex the $WG2PRE/prints/ directory, the
$WG2PRE/wg2/archives/1/wgreindex command can be called from
the crontab (cf. man crontab). As stated before, it is
important to run the reindexing command as the web user. Webglimpse
provides some additional documentation reindexing
from crontab .
To keep installation and maintenance overhead small, BibGlimpse was
built without elaborate user management features. Exploiting simple
directory tree structures and Apache's .htaccess
directory-level configuration files, it is nevertheless easily
possible to enable basic user management functionality; just give
different users their own subdirectories in the indexed tree and
arbitrarily restrict access with .htaccess files inside these
directories. Apart from securing the repository from the outside, this
will for instance also allow you to list all files of usera
with a field search for name=usera# and the last user who
changed an annotation will be displayed on the corresponding
repository site.
To uninstall BibGlimpse you just need to remove the installation directory. If you are still running the local Apache, you have to stop the Apache first:
| cd $WG2PRE; |
| ./BibGlimpse/apache/bin/apachectl -k stop; |
| rm -rf BibGlimpse/; |
In case you were using an existing Apache, you will also have to remove the scripts from its cgi-bin/ directory, as well as the symlink to your prints/ directory from the htdocs/ path.
| rm -rf $WG2PRE/BibGlimpse/; |
| rm -rf $APCGILOC/BibGlimpse/; |
| rm $APHTDOCSLOC/prints; |
BibGlimpse home | Boku Bioinformatics home | Webglimpse home